 |
Provevance Manager: an Implementation of the PROV Standard
- Overview
The Provenance manager (PROV-man) framework provides an implementation of the Provenance Standard (PROV). PROV-man provides functionalities to create and manipulate provenance data in a consistent manner and ensures its permanent storage. It also provides a set of interfaces to serializes and export provenance data into various data format, serving interoperability.
Three main components constitutes the PROV-man farework:
- A set of methods to build and manipulate provenance data, while preserving full compliance with the PROV specifications,
- A set of interfaces for provenance data sharing and interoperation. These interfaces covers serialization to formats of the PROV family of documents (e.g. XML, RDF, DC, etc.) and other specifically required format (e.g. Graphviz, PDF, JPG, etc.), and
- A relational database that serves as a main repository for storing provenance data, reflecting the PROV-man data model.
- Deployment & Download
To use the Prov-man framework, please consider the following steps:
- Download the PROVman-v1.1.jar api
- Download the PROVman-v1.2.jar api
- Download the PROVman-v1.3.jar api
- Create the PROV-man database using this script prov-man.ddl.txt
- When the database is ready, update the database configuration file ( hibernate.cfg.xml) in the Prov-man.jar file, so that it points to the created database, indicating also the user name and password.
After performing the steps above, you are ready to deploy the PROV-man api within your Java-based software application to create and manipulate provenance data.
In the following sections, we provide a Java code sample illustrating how to build provenance data using the Prov-man framework, followed by examples converting the provenance sample to various formats (e.g. JPG, PDF, XML, PROV-N, PROV-O, and DOT)
- Example
The sample java code, presented in figure 1, implements a simple example of an online newspaper article, described in the PROV-PRIMER document. This example illustrates how to create and manipulate data provenance, using PROV-man. The complete code for this example is available sample.java. The example illustrates how to create provenance data objects and how to establish the link between these objects using relationships. Attributes can be created and added to Entities, Activities, Agents, and Relations of different types. Finally, all objects are added to the Document instance, defining the graph of data provenance.

Figure 1: Java sample code illustrating the use of PROV-man for creating and manipulating provenance data.
The example in figure 1 shows also examples of using generic methods provided by PROV-man Factory, which simplifies the creation of provenance data using a syntax similar to PROV-N.
Figure 2 illustrates the PROV-man interfaces for interoperability and data sharing. Currently, the following interfaces are available:
- toDB (document): maps the provenance document from its o-o representation to a relational model, using ORM concepts, and stores it into the database.
- toXML(document): serializes the provenance document to the corresponding XML representation, in compliance with the PROV XML schema (sample.xml).
- toProvN (document): serializes the provenance document to the PROV-N representation (sample.n.txt).
- toOWL2 (document): serializes the provenance document to the corresponding OWL2 representation (sample.owl2.txt).
- toGraphviz (document): translates the provenance document to the Graphviz DOT format (sample.dot.txt).
- toGraph (document, format): generates a graphical representation of the provenance document , according to the specified format (e.g. png, jpg, gif, and pdf) (sample.pdf). This interface relies on the Graphviz software, which support most of the graphical output formats.
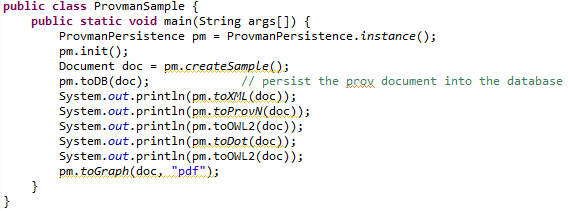
Figure 2: Java sample code illustrating the use of PROV-man interfaces for provenance data conversion.
The corresponding data provenance graph for the on-line newspaper article is depicted on Figure 3. This graph is generated using 'toGraph' interface of PROV-man.
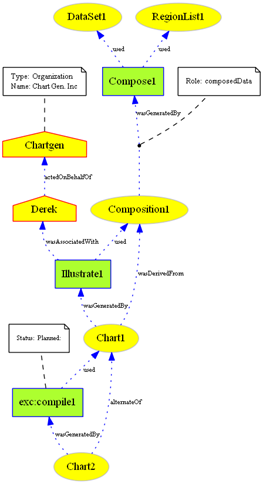
Figure 3 : data provenance graph corresponding to the online newspaper article.
- Documentation
- Download PROV-man Java Doc PROVman-v1.1-javadoc.jar
- PROV-man presentation, AMC, Amsterdam 14-01-2014: PROV-man_AMC 14-01-2014.pdf
- PROV-man presentation SZTAKI, Budapest 24-03-2014: PROV-man overview.pdf
- PROV Overview SZTAKI, Budapest 24-03-2014: PROV overview
Additional Material & References
- The Architecture:
The open architecture of PROV-man, consisting of an API and a configurable database, allows for its easy deployment within existing and newly developed software tools. Figure 4 shows the main components of the framework, consisting of (1) a database implementing the PROV-DM concepts, and (2) a core API implementing the set of methods and interfaces to create and manipulate provenance data represented according to this model.
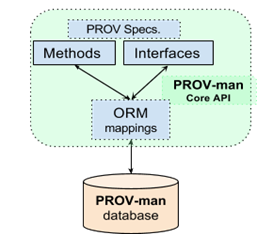
Figure 4: PROV-man architecture consisting of a database and a core API
PROV-man considers the following design requirements:
- The permanent storage of provenance data and the approaches for data optimization regarding..,
- Easy access to provenance data and promotion of data sharing, and
- Easy deployment of the framework in various use cases.
Figure 5 illustrates the open architecture of the PROV-man framework, which allow for its flexible integration into existing and newly developed software tools,
- On one hand existing software tools (e.g. workflow systems) could deploy and integrate PROV-man into their core implementation;
- On the other hand, PROV-man can be used by specific applications and in-house toolboxes. As such, a specific data analysis tool could make use PROV-man to store the fine-grained provenance details
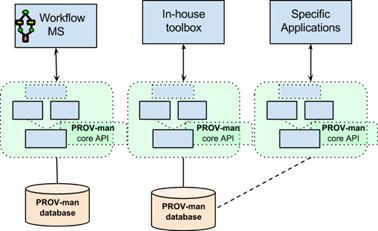
Figure 5: PROV-man follows an open architecture allowing for flexible integration with existing and newly developed software tools
Figure 5 depicts also scenario cases where multiple provenance tools/applications could share the same PROV-man database, which promotes interoperability and data sharing.
- The Data Model
Figure 6 depicts the PROV-man data model after reducing the number of Relationships (sixteen) and consequently their corresponding Attributes (sixteen) to two tables, namely, Relation and RelationAttributes. The optimized PROV-man data model can be seen as a scheme in which, we re-arranged the modeling of the PROV-DM relationships in a manner that reduces its complexity and preserves its full semantics. In section 4.2 we will demonstrate the flexibility of the PROV-man data model in supporting the implementation of the methods to manage the provenance data, following the PROV specifications.
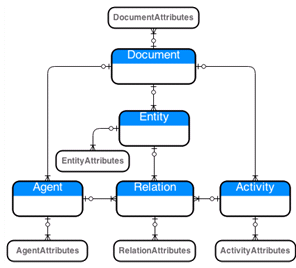
Figure 6: Optimized PROV-man data model. A Document is made of a set of Entities, Activities, and Agents; Relations may be established between the three core data types; and each of the components can be further described using a set of Attributes.
|
|
Last updated: 28/05/2014, A. Benabdelkader
|
|
